Witam, jakiś czas temu w pracy staneliśmy przed dylematem - którą bazę danych użyć? Dyskusja była długa, w końcu postanowiliśmy przetestować wydajność każdego rozwiązania. Niestety testy niejasności tylko jeszcze bardziej naświetliły.
Pierwszy test, jaki przeprowadziliśmy polegał na wstawieniu 3 milionów rekordów do tabeli, która składała się z 5 kolumn.
[sql] – pgsql CREATE TABLE users ( user_id serial NOT NULL, user_name varchar(45), user_password varchar(32), user_first_name varchar(15), user_last_name varchar(15), CONSTRAINT users_pkey PRIMARY KEY (user_id) ) [/sql]
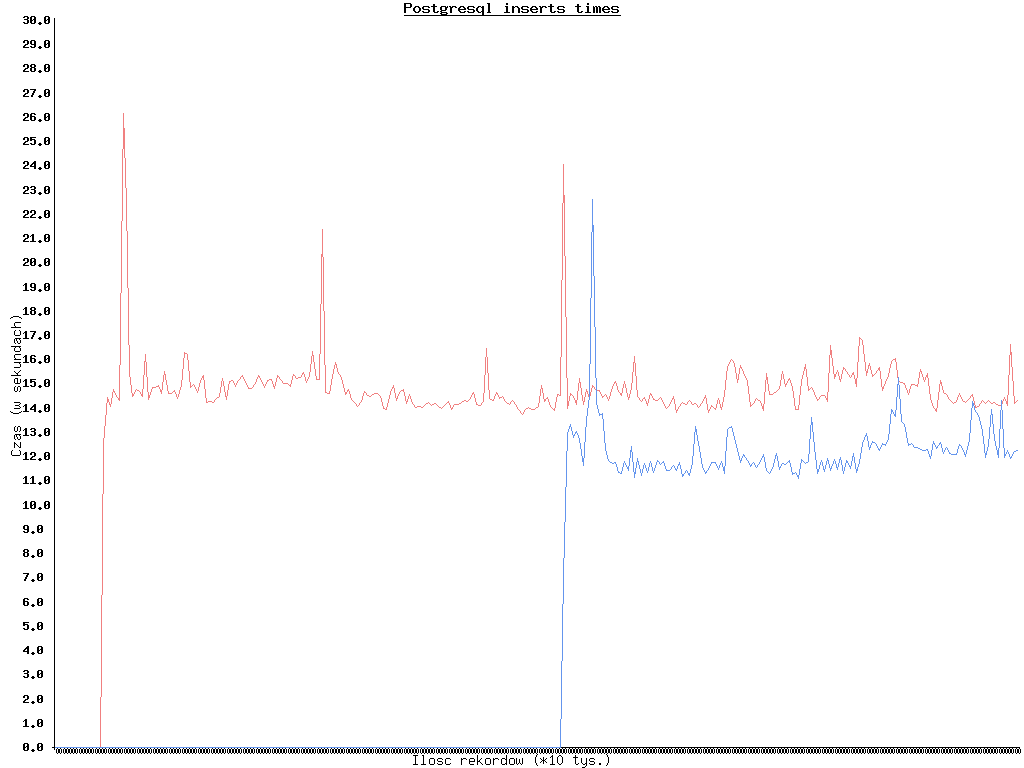 Identyfikator był numerem iteracji, nie wykorzystałem ani autoincrement w MySQL ani sekwencji w PgSQL. Niestety, troszkę się zagapiłem i nie mam czasów dla MySQL do 1.5 mln wstawień i dla PgSQL do 150 tys. Obrazek prezentujący wyniki po lewej. Czerwony - PgSQL, niebieski MySQL. Na dole powinna być ilość rekordów, które są już w bazie, ale ze względu, że zaczęły one na siebie zachodzić powstawiałem zera. W każdym razie im bliżej prawej tym mniej brakuje do 3 mln. Duże skoki w wykonywaniu insertów były spowodowane wykonaniem zapytania z SELECT COUNT(user_id) FROM users.
Jak widać MySQL wyraźnie wygrywa w tym teście z PgSQL. Średnio czas, który MySQL potrzebuje na wstawienie 10 tys rekordów to 12.2204 s. Gdybym dysponował czasami sprzed 1.5 mln rekordów czas ten mógłby ulce zmniejszeniu. PostgreSQL na wstawienie 10 tys rekordów potrzebuje średnio 14.7962 s.
Identyfikator był numerem iteracji, nie wykorzystałem ani autoincrement w MySQL ani sekwencji w PgSQL. Niestety, troszkę się zagapiłem i nie mam czasów dla MySQL do 1.5 mln wstawień i dla PgSQL do 150 tys. Obrazek prezentujący wyniki po lewej. Czerwony - PgSQL, niebieski MySQL. Na dole powinna być ilość rekordów, które są już w bazie, ale ze względu, że zaczęły one na siebie zachodzić powstawiałem zera. W każdym razie im bliżej prawej tym mniej brakuje do 3 mln. Duże skoki w wykonywaniu insertów były spowodowane wykonaniem zapytania z SELECT COUNT(user_id) FROM users.
Jak widać MySQL wyraźnie wygrywa w tym teście z PgSQL. Średnio czas, który MySQL potrzebuje na wstawienie 10 tys rekordów to 12.2204 s. Gdybym dysponował czasami sprzed 1.5 mln rekordów czas ten mógłby ulce zmniejszeniu. PostgreSQL na wstawienie 10 tys rekordów potrzebuje średnio 14.7962 s.
To nie był koniec testów. Ciekawie zaczęło się robić, gdy trzeba było pobrać dane z tej tabeli. Oczywiście do tego celu napisałem algorytm, który losowo odpytuje tabelę z różnym limitem i offsetem oraz różnie sortuje wyniki. Ciekawi co się stało? Zarówno MySQL jak i PgSQL nie poradziły sobie z takim obciążeniem, Pg nie starczało 400 M wolnego miejsca na dysku, w przypadku MySQL nie było o czym gadać, serwer nawet nie zwrócił informacji o niepowodzeniu czy czymkolwiek tylko stanął. Tzn. pracował w dalszym ciągu stabilnie, ale zapytanie po prostu jakby pominął, nic nie zwrócił i dalej nic nie robił.
Jedynym lekarstwem na ten problem okazały się indeksy. Postanowiliśmy, że na początku zindeksujemy wszystkie kolumny (test bez indeksów w przygotowaniu). O ile dodanie indeksów w Pg to nie był problem, wystarczyło mu jakieś 40-60 minut na wszystkie kolumny o tyle w przypadku My problem już powstał. Serwer stworzył tabelę tymczasową i przez 2h nie dodał żadnego indeksu. Jedynym wyjściem było oczyszczenie tabeli. Niestety serwer po wycofaniu się z indeksów przestał odpowiadać. Po restarcie najpierw spróbowałem DELETE FROM users. Nie był to najlepszy pomysł. Restart. DELETE FROM users LIMIT 10000. Restart. DELETE FROM users LIMIT 1000. Restart. DROP TABLE users. Reset. Żadna z tych operacji nie dała skutku. Dopiero po kolejnym resecie udało mi się usunąć tabelę. Tabelę stworzyłem na nowo, dodałem indeksy i zacząłem dodawać dane na nowo. Tym razem czasy zmierzyłem od początku.
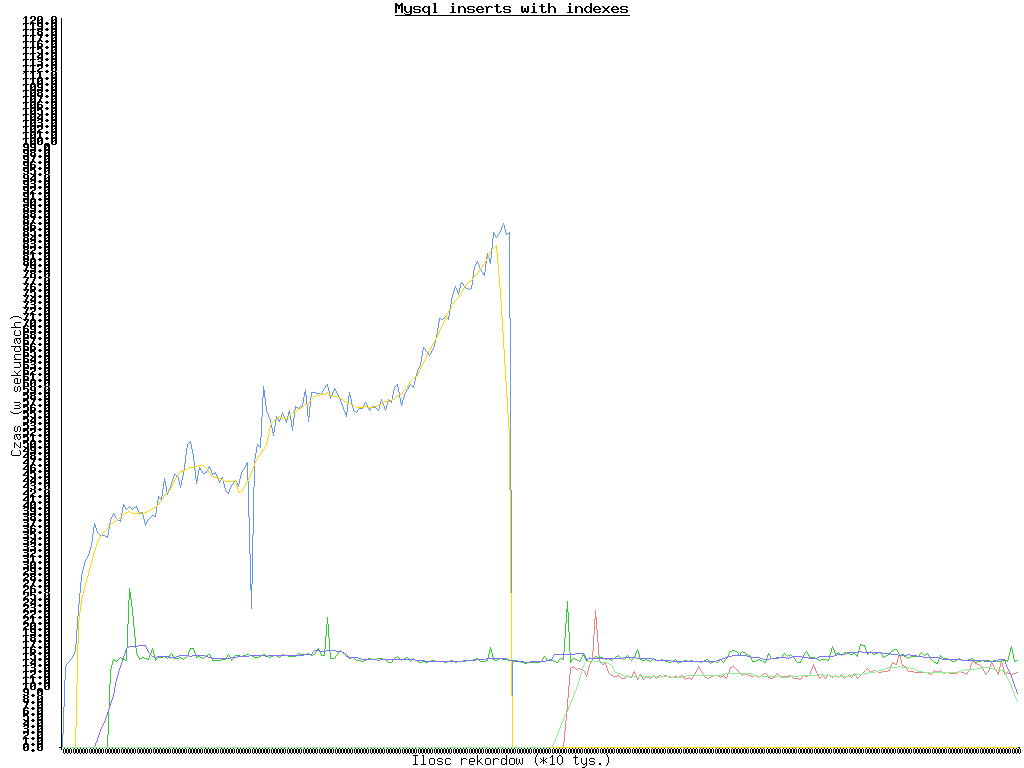 Wynik? Straszny. Czasy zaczęły lecieć na łeb, na szyję. O ile z początku jakoś to się trzymało, to później został przekroczony próg 30 s na 10 tys rekordów, następnie 50 aż doszliśmy do 85 s. Przy 1.5 mln rekordów przerwałem test.
Wynik? Straszny. Czasy zaczęły lecieć na łeb, na szyję. O ile z początku jakoś to się trzymało, to później został przekroczony próg 30 s na 10 tys rekordów, następnie 50 aż doszliśmy do 85 s. Przy 1.5 mln rekordów przerwałem test.
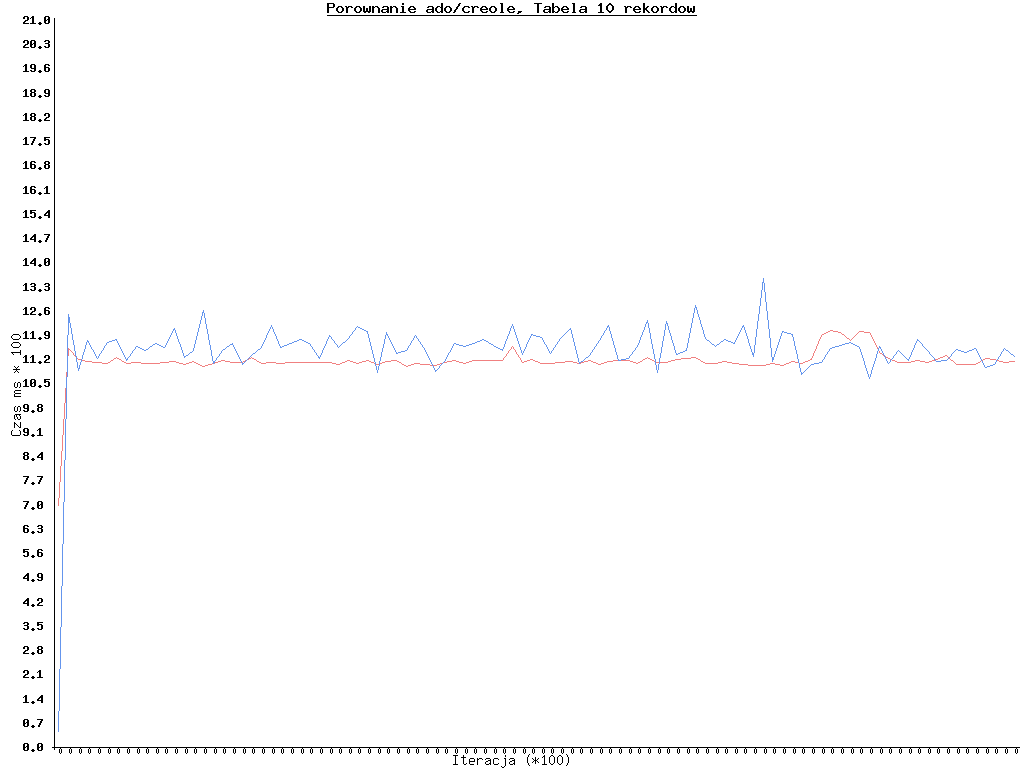
Oprócz testów baz danych przetestowałem również na o wiele mniejszej tabeli (5 kolumn, 10 wierszy, pobranie wszystkich z losowym sortowaniem, 10 tys iteracji) AdoDB i Creole. AdoDB korzystało z PDO, Creole z natywnych funkcji. Nie bierzcie tego testu na poważnie.. Ciąg dalszy testów być może nastąpi. :) Dziękuję firmie Autoguard za pozwolenie na publikację testów.